Regular expressions are powerful pattern-matching tools. They use a specialized syntax to define search patterns within strings. In Ruby, these patterns are typically written as literals enclosed in slashes (e.g., /pattern/) or, more flexibly, using the %r operator followed by arbitrary delimiters (e.g., %r{pattern}).

Syntax
/pattern/
/pattern/im # option can be specified
%r!/usr/local! # general delimited regular expressionExample
#!/usr/bin/ruby
line1 = "Cats are smarter than dogs";
line2 = "Dogs also like meat";
if ( line1 =~ /Cats(.*)/ )
puts "Line1 contains Cats"
end
if ( line2 =~ /Cats(.*)/ )
puts "Line2 contains Dogs"
endThis will result in the following outcome:
Line 1 has cats.Ruby Regex Modifiers
Ruby’s regular expression literals can be fine-tuned using optional modifiers placed after the closing slash. These modifiers, represented by single characters, alter the matching behavior in various ways.
| Sr.No. | Modifier & Description |
|---|---|
| 1 | i Case is ignored when matching text. |
| 2 | o Carries out #{} interpolations just once, during the initial evaluation of the regexp literal. |
| 3 | x Enables comments in regular expressions and ignores whitespace. |
| 4 | m Matches several lines and accepts newlines as standard characters. |
| 5 | u,e,s,n Considers the regexp to be ASCII, EUC, SJIS, or Unicode (UTF-8). It is presumed that the regular expression uses the source encoding if none of these modifiers are supplied. |
Ruby lets you start regular expressions with %r and then a delimiter of your choice, just like string literals delimited with %Q. When the pattern you are describing has a lot of forward slash characters that you don’t want to escape, this is helpful.
# Following matches a single slash character, no escape required
%r|/|
# Flag characters are allowed with this syntax, too
%r[</(.*)>]iUnderstanding Ruby Regex Patterns
Every character matches itself, with the exception of the control characters (+ ? . * ^ $ ( ) [ ] { } | / ). By using a backslash before a control character, you can get out of it.
The following table details Ruby’s regular expression syntax.
| Sr.No. | Pattern & Description |
| 1 | ^ Matches beginning of line. |
| 2 | $ Matches end of line. |
| 3 | . Matches any single character except newline. Using m option allows it to match newline as well. |
| 4 | […] Matches any single character in brackets. |
| 5 | [^…] Matches any single character not in brackets |
| 6 | re* Matches 0 or more occurrences of preceding expression. |
| 7 | re+ Matches 1 or more occurrence of preceding expression. |
| 8 | re? Matches 0 or 1 occurrence of preceding expression. |
| 9 | re{ n} Matches exactly n number of occurrences of preceding expression. |
| 10 | re{ n,} Matches n or more occurrences of preceding expression. |
| 11 | re{ n, m} Matches at least n and at most m occurrences of preceding expression. |
| 12 | a| b Matches either a or b. |
| 13 | (re) Groups regular expressions and remembers matched text. |
| 14 | (?imx) Temporarily toggles on i, m, or x options within a regular expression. If in parentheses, only that area is affected. |
| 15 | (?-imx) Temporarily toggles off i, m, or x options within a regular expression. If in parentheses, only that area is affected. |
| 16 | (?: re) Groups regular expressions without remembering matched text. |
| 17 | (?imx: re) Temporarily toggles on i, m, or x options within parentheses. |
| 18 | (?-imx: re) Temporarily toggles off i, m, or x options within parentheses. |
| 19 | (?#…) Comment. |
| 20 | (?= re) Specifies position using a pattern. Doesn’t have a range. |
| 21 | (?! re) Specifies position using pattern negation. Doesn’t have a range. |
| 22 | (?> re) Matches independent pattern without backtracking. |
| 23 | \w Matches word characters. |
| 24 | \W Matches nonword characters. |
| 25 | \s Matches whitespace. Equivalent to [\t\n\r\f]. |
| 26 | \S Matches nonwhitespace. |
| 27 | \d Matches digits. Equivalent to [0-9]. |
| 28 | \D Matches nondigits. |
| 29 | \A Matches beginning of string. |
| 30 | \Z Matches end of string. If a newline exists, it matches just before newline. |
| 31 | \z Matches end of string. |
| 32 | \G Matches point where last match finished. |
| 33 | \b Matches word boundaries when outside brackets. Matches backspace (0x08) when inside brackets. |
| 34 | \B Matches non-word boundaries. |
| 35 | \n, \t, etc. Matches newlines, carriage returns, tabs, etc. |
| 36 | \1…\9 Matches nth grouped subexpression. |
| 37 | \10 Matches nth grouped subexpression if it matched already. Otherwise refers to the octal representation of a character code. |
Literal Characters
| Sr.No. | Example & Description |
| 1 | /ruby/ Matches “ruby”. |
| 2 | ¥ Matches Yen sign. Multibyte characters are supported in Ruby 1.9 and Ruby 1.8. |
Character Classes
| Sr.No. | Example & Description |
| 1 | /[Rr]uby/ Matches “Ruby” or “ruby”. |
| 2 | /rub[ye]/ Matches “ruby” or “rube”. |
| 3 | /[aeiou]/ Matches any one lowercase vowel. |
| 4 | /[0-9]/ Matches any digit; same as /[0123456789]/. |
| 5 | /[a-z]/ Matches any lowercase ASCII letter. |
| 6 | /[A-Z]/ Matches any uppercase ASCII letter. |
| 7 | /[a-zA-Z0-9]/ Matches any of the above. |
| 8 | /[^aeiou]/ Matches anything other than a lowercase vowel. |
| 9 | /[^0-9]/ Matches anything other than a digit. |
Special Character Classes
| Sr.No. | Example & Description |
| 1 | /./ Matches any character except newline. |
| 2 | /./m In multi-line mode, matches newline, too. |
| 3 | /\d/ Matches a digit: /[0-9]/. |
| 4 | /\D/ Matches a non-digit: /[^0-9]/. |
| 5 | /\s/ Matches a whitespace character: /[ \t\r\n\f]/. |
| 6 | /\S/ Matches non-whitespace: /[^ \t\r\n\f]/. |
| 7 | /\w/ Matches a single word character: /[A-Za-z0-9_]/. |
| 8 | /\W/ Matches a non-word character: /[^A-Za-z0-9_]/. |
Repetition Cases
| Sr.No. | Example & Description |
| 1 | /ruby?/ Matches “rub” or “ruby”: the y is optional. |
| 2 | /ruby*/ Matches “rub” plus 0 or more ys. |
| 3 | /ruby+/ Matches “rub” plus 1 or more ys. |
| 4 | /\d{3}/ Matches exactly 3 digits. |
| 5 | /\d{3,}/ Matches 3 or more digits. |
| 6 | /\d{3,5}/ Matches 3, 4, or 5 digits. |
Non-greedy Repetition
| Sr.No. | Example & Description |
| 1 | /<.*>/ Greedy repetition: matches “<ruby>perl>”. |
| 2 | /<.*?>/ Non-greedy: matches “<ruby>” in “<ruby>perl>”. |
Grouping with Parentheses
| Sr.No. | Example & Description |
| 1 | /\D\d+/ No group: + repeats \d |
| 2 | /(\D\d)+/ Grouped: + repeats \D\d pair |
| 3 | /([Rr]uby(, )?)+/ Match “Ruby”, “Ruby, ruby, ruby”, etc. |
Back References
| Sr.No. | Example & Description |
| 1 | /([Rr])uby&\1ails/ Matches ruby&rails or Ruby&Rails. |
| 2 | /([‘”])(?:(?!\1).)*\1/ Single or double-quoted string. \1 matches whatever the 1st group matched . \2 matches whatever the 2nd group matched, etc. |
Alternatives
| Sr.No. | Example & Description |
| 1 | /ruby|rube/ Matches “ruby” or “rube”. |
| 2 | /rub(y|le))/ Matches “ruby” or “ruble”. |
| 3 | /ruby(!+|\?)/ “ruby” followed by one or more ! or one ? |
Anchors
| Sr.No. | Example & Description |
| 1 | /^Ruby/ Matches “Ruby” at the start of a string or internal line. |
| 2 | /Ruby$/ Matches “Ruby” at the end of a string or line. |
| 3 | /\ARuby/ Matches “Ruby” at the start of a string. |
| 4 | /Ruby\Z/ Matches “Ruby” at the end of a string. |
| 5 | /\bRuby\b/ Matches “Ruby” at a word boundary. |
| 6 | /\brub\B/ \B is non-word boundary: matches “rub” in “rube” and “ruby” but not alone. |
| 7 | /Ruby(?=!)/ Matches “Ruby”, if followed by an exclamation point. |
| 8 | /Ruby(?!!)/ Matches “Ruby”, if not followed by an exclamation point. |
Special Syntax with Parentheses
| Sr.No. | Example & Description |
| 1 | /R(?#comment)/ Matches “R”. All the rest is a comment. |
| 2 | /R(?i)uby/ Case-insensitive while matching “uby”. |
| 3 | /R(?i:uby)/ Same as above. |
| 4 | /rub(?:y|le))/ Group only without creating \1 backreference. |
String Manipulation with Regex in Ruby
Sub, gsub, and their in-place versions sub! are some of the most significant String techniques that make use of regular expressions. as well as gsub.
All of these strategies perform a search-and-replace operation utilizing a Regexp design. The sub & sub! replaces the to begin with event of the design and gsub & gsub! replaces all events.
The sub and gsub returns a unused string, clearing out the unique unmodified whereas sub! and gsub! adjust the string on which they are called.
Here’s an example:
#!/usr/bin/ruby
phone = "2004-959-559 #This is Phone Number"
# Delete Ruby-style comments
phone = phone.sub!(/#.*$/, "")
puts "Phone Num : #{phone}"
# Remove anything other than digits
phone = phone.gsub!(/\D/, "")
puts "Phone Num : #{phone}"This will result in the following outcome –
Phone Num : 2004-959-559
Phone Num : 2004959559
Here’s an example:
#!/usr/bin/ruby
text = "rails are rails, really good Ruby on Rails"
# Change "rails" to "Rails" throughout
text.gsub!("rails", "Rails")
# Capitalize the word "Rails" throughout
text.gsub!(/\brails\b/, "Rails")
puts "#{text}"The outcome of this will be as follows –
Rails is Rails, and Ruby on Rails is excellent.Accessing Databases in Ruby with DBI
This chapter shows you how to use Ruby to access a database. Like the Perl DBI module, the Ruby DBI module offers a database-independent interface for Ruby scripts.\
Database Independent Interface for Ruby, or DBI for short, offers an abstraction layer between the underlying database and the Ruby code, making it simple to transition between database implementations. Regardless of the database being used, it specifies a collection of variables, rules, and procedures that offer a standardized database interface.
The following can be interfaced with using DBI:
- ADO (ActiveX Data Objects)
- DB2
- Frontbase
- mySQL
- MySQL
- ODBC
- Oracle
- OCI8 (Oracle)
- PostgreSQL
- Proxy/Server
- SQLite
- SQLRelay
DBI Application Structure
Any database that is accessible in the backend has no bearing on DBI. Regardless of whether you are working with Oracle, MySQL, Informix, etc., you can use DBI. The architecture diagram that follows makes this very evident.
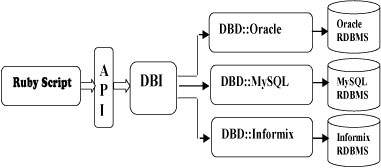
Two layers make up Ruby DBI’s general architecture.
- The DBI layer is the database interface. Regardless of the sort of database server you’re interacting with, this layer offers a consistent set of access methods that are database independent.
- The DBD layer is the database driver. Different drivers grant access to various database engines, making this layer database dependent. One driver exists for MySQL, another for PostgreSQL, another for Oracle, and so on. Each driver translates DBI layer requests into requests that are suitable for a certain kind of database server.
Essential Requirements
You must have the Ruby MySQL module installed in order to develop Ruby scripts that access MySQL databases.
As previously mentioned, this module functions as a DBD and is available for download from https://www.tmtm.org/en/mysql/ruby/
Setting up Ruby/DBI
Install the Ruby DBI library via the RubyGems package manager.
gem install dbiMake sure you have root access before beginning this installation. Now, take the actions listed below.
Step 1
$ tar zxf dbi-0.2.0.tar.gzStep 2: Navigate to the distribution directory dbi-0.2.0 and use the setup.rb script located there to configure it. This is how the most basic configuration command appears, with the config parameter followed by no arguments. The distribution is set up to install all drivers by default with this command.
$ ruby setup.rb configCustomize your DBI installation by specifying drivers using the --with option. For example, ruby setup.rb config --with=dbi,dbd-mysql installs only the core DBI module and the MySQL driver.
$ ruby setup.rb config --with = dbi,dbd_mysqlStep 3: The last step is to use the following commands to develop and install the driver:
$ ruby setup.rb setup
$ ruby setup.rb installEstablishing a Database Connection
Make sure of the following before connecting to a database, assuming we’ll be working with a MySQL database –
- TESTDB is the database that you have constructed.
- EMPLOYEE was created by you in TESTDB.
- This table has the following fields: AGE, SEX, INCOME, FIRST_NAME, LAST_NAME.
- The password “test123” and user ID “testuser” are configured to access TESTDB.
- Your computer has a correctly installed Ruby Module DBI.
- To learn the fundamentals of MySQL, you have completed the tutorial.
Here is an example of connecting to the “TESTDB” MySQL database.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
# get server version string and display it
row = dbh.select_one("SELECT VERSION()")
puts "Server version: " + row[0]
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endThis script generates the following outcome on our Linux computer when it runs.
Server version: 5.0.45After establishing a connection with the data source, a Database Handle is returned and stored in dbh for future use; if not, dbh is set to nil, and e.err and e::errstr return an error string and an error code, respectively.
Data Insertion
Be sure to end the database connection and release the resources before exiting.
To generate your records in a database table, you must use the INSERT operation.
We can use the do method or prepare and execute method to build tables or records into the database tables once a database connection has been made.
Understanding do Statements
Execute non-result-returning SQL statements using the database handle’s do method, which returns the number of affected rows.
dbh.do("DROP TABLE IF EXISTS EMPLOYEE")
dbh.do("CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )" );To add a record to the EMPLOYEE table, use the SQL INSERT statement in a similar manner.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
dbh.do( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)" )
puts "Record has been created"
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endprepare and execute Methods:
Applying prepare and execute
To run the SQL statement using Ruby code, utilize the prepare and execute methods of the DBI class.
To create a record, complete these steps:
- INSERT statement for SQL statement preparation. The prepare method will be used to accomplish this.
- Carrying out a SQL query to choose every database result. We’ll use the execute method to accomplish this.
- Handle for the releasing statement. We’ll use the finish API for this.
- If everything goes fine, then commit this operation otherwise you can rollback the complete transaction.
The syntax to utilize these two techniques is as follows –
sth = dbh.prepare(statement)
sth.execute
... zero or more SQL operations ...
sth.finishSQL statements can be passed bind values using one of these two techniques. In certain situations, the values that need to be entered might not be specified beforehand. In this situation, binding values are applied. Before actual values are supplied through the execute() API, a question mark (?) is used in their place.
Here’s how to add two records to the EMPLOYEE table:
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (?, ?, ?, ?, ?)" )
sth.execute('John', 'Poul', 25, 'M', 2300)
sth.execute('Zara', 'Ali', 17, 'F', 1000)
sth.finish
dbh.commit
puts "Record has been created"
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endIt is more effective to prepare a statement first and then run it again within a loop if there are numerous INSERTs occurring at once rather than calling do each time.
Reading Data from the Database
Any database’s READ operation allows you to retrieve some helpful data from it.
We are prepared to run a query into this database once we have established a database connection. To retrieve values from a database table, we can either use the do method or prepare and execute methods.
The steps involved in retrieving records are as follows:
- creating a SQL query according to the necessary criteria. We’ll use the prepare method to accomplish this.
- Running a SQL query to retrieve every database result. The execute method will be used for this.
- Obtaining each result individually and printed it. The fetch method will be used for this.
- Handle for the releasing statement. The finish procedure will be used for this.
The steps to query every record in the EMPLOYEE table with a salary above 1,000 are as follows.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("SELECT * FROM EMPLOYEE WHERE INCOME > ?")
sth.execute(1000)
sth.fetch do |row|
printf "First Name: %s, Last Name : %s\n", row[0], row[1]
printf "Age: %d, Sex : %s\n", row[2], row[3]
printf "Salary :%d \n\n", row[4]
end
sth.finish
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endThis will result in the following outcome −
First Name: Mac, Last Name : Mohan
Age: 20, Sex : M
Salary :2000
First Name: John, Last Name : Poul
Age: 25, Sex : M
Salary :2300To retrieve records from the database, there are more shortcut techniques. Go through the “Fetching the Result” part if you’re interested, otherwise move on to the next one.
Update Operation
To update one or more records that are already present in the database, use the UPDATE operation. The steps to update all records with SEX as ‘M’ are as follows. In this case, we shall raise each male’s age by one year. There will be three steps involved.
- Creating a SQL query based on the necessary parameters. We’ll use the prepare method to accomplish this.
- Selecting every result from the database by running a SQL query. We’ll use the execute method to accomplish this.
- Handling of the releasing statement. We’ll use the finish method for this.
- If everything goes fine then commit this operation otherwise you can rollback the complete transaction
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = ?")
sth.execute('M')
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endRemoving Database Records
You must perform a DELETE operation in order to remove certain records from your database. The steps below will remove all employee records where the employee’s age exceeds 20. The steps below will be taken in this operation.
- Creating a SQL query based on the necessary parameters. We’ll use the prepare method to accomplish this.
- Running a SQL query to remove necessary database records. We’ll use the execute method to accomplish this.
- Handling of the releasing statement. We’ll use the finish method for this.
- If everything goes according to plan, proceed with this operation; if not, you can reverse the entire transaction.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("DELETE FROM EMPLOYEE WHERE AGE > ?")
sth.execute(20)
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endManaging Transactions
Data consistency is ensured by transactions. The four properties listed below should be present in transactions
- Atomicity − Either nothing occurs or a transaction is completed.
- Consistency −Every transaction must begin and end in the same condition within the system.
- Isolation − The intermediate outcomes of a transaction are not accessible to those who are not involved in it.
- Durability − The consequences of a transaction remain after it has been committed, even in the event of a system failure.
There are two ways to commit or rollback a transaction using the DBI. To carry out transactions, there is an additional technique known as transaction. There are two easy ways to put transactions into practice.
Approach I
The first technique commits or cancels the transaction explicitly using DBI’s commit and rollback capabilities.
The first technique commits or cancels the transaction explicitly using DBI’s commit and rollback capabilities.
dbh['AutoCommit'] = false # Set auto commit to false.
begin
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
dbh.commit
rescue
puts "transaction failed"
dbh.rollback
end
dbh['AutoCommit'] = trueApproach II
The second strategy makes advantage of the transaction technique. This is easier since it uses a code block that contains the statements that comprise the transaction. After the block is executed, the transaction mechanism automatically initiates commit or rollback, according on whether the block is successful or unsuccessful.
dbh['AutoCommit'] = false # Set auto commit to false.
dbh.transaction do |dbh|
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
end
dbh['AutoCommit'] = trueCommitting Database Changes
Commit is the action that authorizes the database to complete the modifications; once this is done, no changes can be undone.
The commit method can be called in this straightforward example.
dbh.commitRollback in Databases
To revert any unwanted changes made during a database transaction, use the rollback method. This completely reverses all modifications made since the transaction began.
This is a basic example of how to invoke the rollback method .
dbh.rollbackDatabase Disconnection
Use the disconnect API to end the database connection.
dbh.disconnectTroubleshooting Errors
Errors can come from many different sources. A connection failure, a syntax mistake in a SQL statement that has already been performed, or using the fetch method for a statement handle that has already been canceled or completed are a few instances.
DBI raises an exception if one of its methods fails. Although DBI methods can raise any of a number of exception types, DBI::InterfaceError and DBI::DatabaseError are the two most significant exception classes.
The error number, a descriptive error message, and a standard error code are represented by the three attributes err, errstr, and state that are present in exception objects of these kinds. The characteristics are described below.
- err − Returns the numerical portion of an ORA-XXXX error message, for instance, or nil if the DBD does not support it. Returns an integer representation of the error that occurred.
- errstr − Returns back a string describing the error that happened.
- state − Returns back the SQLSTATE code for the error that occurred. The SQLSTATE is a string of five characters. The majority of DBDs return nil instead of supporting this.
You’ve seen the code above in the majority of the examples−
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endYou can activate tracing to obtain debugging information about the actions of your script while it runs. This is accomplished by calling the trace method, which regulates the trace mode and output destination, after loading the dbi/trace module.
require "dbi/trace"
..............
trace(mode, destination)The destination should be an IO object, and the mode value can be either 0 (off), 1, 2, or 3. STDERR and 2 are the default values, respectively.
Code Blocks Containing Methods
Certain techniques generate handles. A code block can be used to call these methods. Using code blocks in conjunction with methods has the benefit of automatically cleaning up the handle after the block ends and providing the handle to the code block as a parameter. There aren’t many examples to help you grasp the idea.
- DBI.connect − This method creates a database handle, and in order to detach the database, it is advised to execute disconnect at the end of the block.
- dbh.prepare − This technique is best used at the end of the block as it creates a statement handle. To execute the statement, you must call the execute method inside the block.
- dbh.execute − This method is comparable, but it does not require using execute inside the block. It automatically executes the statement handle.
Example 1
A code block can be passed to DBI.connect, which then automatically disconnects the database handle at the end of the block –
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123") do |dbh|Example 2
A code block can be passed to dbh.prepare, which then automatically calls finish at the end of the block in the manner described below –
dbh.prepare("SHOW DATABASES") do |sth|
sth.execute
puts "Databases: " + sth.fetch_all.join(", ")
endExample 3
A code block can be passed to dbh.execute, which then automatically calls finish at the end of the block as follows. −
dbh.execute("SHOW DATABASES") do |sth|
puts "Databases: " + sth.fetch_all.join(", ")
end
The code block mentioned above is also used by the DBI transaction mechanism.
Driver-Specific Capabilities
Through the func method of any Handle object, the user can invoke additional database-specific functions that the DBI permits the database drivers to expose.
Using the [] = or [] methods, driver-specific attributes can be set or retrieved.
The DBD::Mysql driver provides these functions:
| Sr.No. | Functions & Description |
| 1 | dbh.func(:createdb, db_name) Creates a new database. |
| 2 | dbh.func(:dropdb, db_name) Drops a database. |
| 3 | dbh.func(:reload) Performs a reload operation. |
| 4 | dbh.func(:shutdown) Shuts down the server. |
| 5 | dbh.func(:insert_id) => Fixnum Returns the most recent AUTO_INCREMENT value for a connection. |
| 6 | dbh.func(:client_info) => String Returns MySQL client information in terms of version. |
| 7 | dbh.func(:client_version) => Fixnum Returns client information in terms of version. It’s similar to :client_info but it return a fixnum instead of sting. |
| 8 | dbh.func(:host_info) => String Returns host information. |
| 9 | dbh.func(:proto_info) => Fixnum Returns protocol being used for the communication. |
| 10 | dbh.func(:server_info) => String Returns MySQL server information in terms of version. |
| 11 | dbh.func(:stat) => String Returns current state of the database. |
| 12 | dbh.func(:thread_id) => Fixnum Returns current thread ID. |
Example
#!/usr/bin/ruby
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
puts dbh.func(:client_info)
puts dbh.func(:client_version)
puts dbh.func(:host_info)
puts dbh.func(:proto_info)
puts dbh.func(:server_info)
puts dbh.func(:thread_id)
puts dbh.func(:stat)
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
dbh.disconnect if dbh
endThis will result in the following outcome –
5.0.45
50045
Localhost via UNIX socket
10
5.0.45
150621
Uptime: 384981 Threads: 1 Questions: 1101078 Slow queries: 4 \
Opens: 324 Flush tables: 1 Open tables: 64 \
Queries per second avg: 2.860